Introduction
Social science is undergoing a revolution. The rise of social media, smart cities, digital archives, quantified selving, and personal agents is providing an unprecedented amount of data about the social relations and behaviors of very large groups of people, creating an opportunity to a more empirically grounded social theory. But this opportunity can only be realized by using powerful tools: for analyzing textual data, for finding patterns in data, and for visualizing those patterns in a way that brings out their meaning. These tools increasingly rely on complex systems science and Artificial Intelligence.
At the same time we see that collective decision-making in contemporary societies is also undergoing profound change. Social media, Big Data, and AI are already having a profound impact on political and social processes. They have empowered ‘citizen-driven’ political movements such as the Arab spring or the French ‘Gilets Jaunes’ protests. They also provide new means to strategically influence public opinion as it was seen before the the Brexit refendum and the US presidential elections in 2016. Similarly, they could lead to rapid polarizations in political debates, such as those concerning migration or identity, and accelerate the spreading of fake news or hate speech.
These dynamics were the focus of the recent ODYCCEUS summer school on ‘Democracy in the Age of Big Data and AI’. In honour of the FETFX Future Tech Week, this page presents some of the summer school’s outcomes, demonstrating the on-going development and potential applications of media-monitoring tools in the Penelope ecosystem.
Building (social) media observatories
The ODYCCEUS summer school mixed theoretical lectures with practical hands-on sessions and ateliers to examine how novel tools of computational social science can help us understand these phenomena and possibly facilitate future democratic decision processes. It introduces social scientists and media researchers to the latest methods, tools, and techniques and introduces AI researchers and complex systems scientists to the approaches and issues of social science so that they can come up with new tools or refine existing ones.

More specifically, participants learned how they could build Opinion Observatories that tap into social media to collect information about how certain actors are trying to manipulate political opinion in elections, how fake news gets fabricated and spreads, or how opinions get polarized and shift. To this end, participants engaged in a series of ateliers guided by tutors, each of which addressed a case study. Case studies considered a specific contentious issue using specific data sources.

Case 1: Climate Change (tutored by Artificial Intelligence Lab, Vrije Universiteit Brussel)
In this workshop, participants used data from the news website of the Guardian and Penelope components to develop a ‘science tracker’: a pipeline to reveal and track references to scientific publications and research institutions in news articles and comments related to climate change. Participants have thus built components to trace the relationships between scientific references and articles and those in news website commentaries, the occurrence of scientific references in articles over time, etc. As such, they have laid a basis for a further exploration of the role of scientific literature within the climate change debate.
Case 2: Antagonisms, coalitions and populism (tutored by Max Planck Institute for Mathematics in the Natural Sciences, Leipzig)
The participants of the workshop decided to focus on a very specific discourse, which took place in the shadow of the big Brexit topic dominating UK politics: The debate about badger cullings in the UK due to the high number of cases of bovine tubercolosis among cattle. The illness is partly spread by the badger population in the UK and Department for Environment, Food and Rural Affairs has hence initiated culling of badgers to reduce the reservoir of infection in wildlife.
Two data sources were used in the workshop: Twitter posts of the week of the Summer School, and all parliamentary speeches by the UK House of Commons since 2016. The aim was to produce an analysis allowing and making use of both close and distant reading to gain a comprehensive view of the debate.
Starting off with relatively close reading of the culling debate in the UK parliament, a new component was introduced and applied to the speeches: Statement graphs. There, sentences including the same words are linked to each other, which yields an overview about the language and topic structure of speeches and can be used to visualize differences and similarities in the use of expressions and words of different parties and politicians, or at different times.
The participants then analyzed the language of the different parties in the UK parliament, and found that the two major parties of the UK talk differently about the cullings: Labour politicians in a more detailed and emotional way, Tories in more abstract and rational terms.
Twitter was used to get an impression about the discourse on social media. Traffic on Twitter was accelerated by the announcement of extending the culling to eleven new areas on September 11. Analysis of the retweet network of posts including ‘badger‘ and ‘cull‘ showed that, to a big extent, only the voices opposing the culling measures were present and shared on Twitter. Statements in favour of the cullings were largely missing. An interesting follow-up question hence arose: How do we deal with data that is not there?
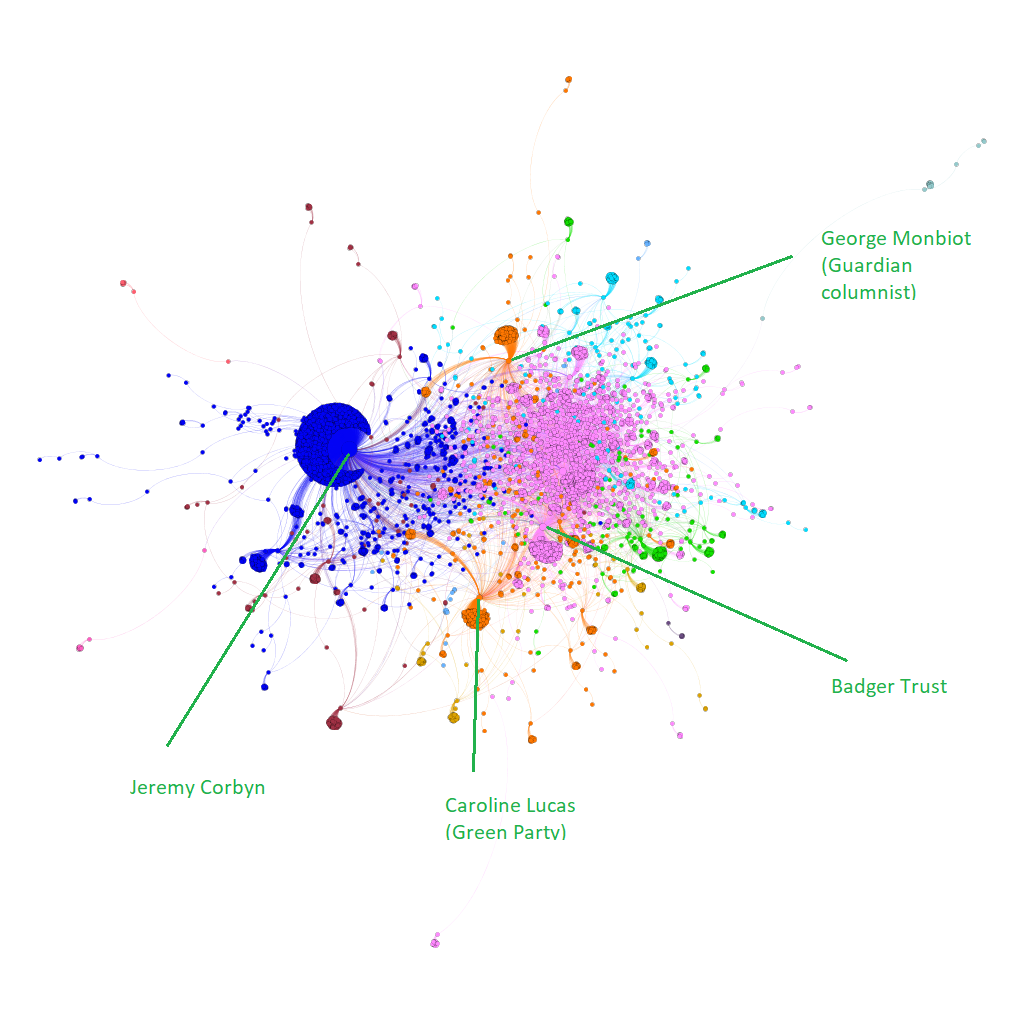
The results showed that even for a ‘minor‘ political topic (compared to and overshadowed by the very heated Brexit debate going on at the same time), the methods and pipelines the participants used and developed provided valuable insights on different scales of data aggregation and visualization, from close to distant reading. This is what should be pursued further in the on-going development of Penelope. The simple visualization techniques of the statement and retweet graphs turned out to provide a valuable systematic perspective on the data. Also more qualitatively oriented researchers can profit from those tools, that we plan to provide to Penelope soon.
Click here for the full presentation
Click here for a demonstrator with the statement graph
Case 3: Hate and excitable speech (tutored by the University of Amsterdam)
This group’s project was aimed at mapping and tracing the spread of extreme speech and hate speech across online platforms. This involved a number of datasets across the one-year interval surrounding the election of Donald Trump as US president in November 2016. Two datasets were of particular interest here, one sourced from 4chan, an anonymous and ephemeral web forum that over the past few years has become increasingly prominent as a breeding ground of far right conspiracy theories and discourse. The other consisted of all comments left by users on Breitbart, a more traditional right-wing news site which emerged as an important supporter of Donald Trump’s campaign in 2016.
One strand of the research focused on a semantic analysis of these datasets. Using a word2vec analysis based on an expert list of known ‘antagonistic’ phrases on the platform – phrases used to identify either the ingroup (e.g. 4chan and its users) or the outgroup (those outside the forum’s subculture, ‘normies’ in 4chan vernacular), the full dataset could then be processed to see how particular phrases or topics could be mapped on this ingroup-versus-outgroup axis. This gave coherent results for a range of topics, from news outlets (where the right-wing Fox News ranked consistently ‘closer’ to the right-wing datasets than neutral or left-wing outlets) to political candidates (where Donald Trump was, unsurprisingly, closer, while Democrat Bernie Sanders was the furthest outward), providing an empirical and quantified impression of the self-described political identity of these ‘exciteable’ discussion spaces.
A second strand of research focused on tracing of one particular ‘phrasal meme’, the far right conspiracy theory of ‘white genocide’, which suggests that the ‘white race’ is under constant threat from immigration and miscegenation. By first subsetting all posts from the 4chan and Breitbart datasets containing this phrase, and then looking for ‘neologisms’ – that is, words not found in other language spaces – we formed an overview of topics discussed in relation to white genocide in these spaces. This produced two interesting insights. First, the semantic context of white genocide, as defined by these neologisms, is remarkably different between the spaces; while on 4chan the discussion is clearly focused on traditional antisemitic theories, Breitbart is quite specifically concerned with the ‘kalergi plan’, a related conspiracy theory. This shows how a current far right talking point can manifest differently in different online discussion spaces. Secondly, the discussion of ‘white genocide’ on especially Breitbart seemed to be completely divorced from the articles published by the outlet, suggesting that the comments section on the site is not so much a place to react to whatever it publishes, but rather a more general right-wing discussion forum where people simply continue an on-going ideological discussion.
Major parts of this research were conducted using 4CAT, a Penelope-based research tool, which allowed for a rapid iterative approach to data analysis. In this way, it also served as a testbed for these technologies, and demonstrated that through the use of a unified interface on top of existing analytical pathways, researchers from various backgrounds can effectively engage with large datasets.
Case 4: Migration and borders (tutored by the University of Paris, 7)
The outcomes of this workshop were documented in Claude Grasland (1), Romain Leconte (1), Etienne Toureille (1), Robin Lamarche-Perrin (2), Hong-Lan Botterman (2), Camilla Ferri( 3), Marloes Geboers (4), Audrey Lisador (1), Remy Poulain (2), Armin Pournaki (5), Thomas Rosenthal (6), ‘A multidimensional perspective on the salience analysis of migration in the press The case of 14 European newspapers (2014-2018)’ Socius (in preparation).
Abstract
The idea of “migrant crisis” has been criticized by migrations studies as an artefact produced by the public sphere. Nonetheless, this idea has spread worldly. This article proposes to study the salience of news related to migrations in a corpus of European press during a fiveyears period (2014-2018). When it comes to the comparison between different sources, between different languages and national contexts, methodological obstacles arise. Salience analysis should take in charge the social complexity by a cross-dimensional perspective. First, we propose a methodology for building a multi-sources, multinational and multi-languages corpusand to identify the topic. Then, the analysis reveals that the salience of migration in the press is not as global as supposed. Important differences of coverage exist. Thanks to an online platform, observations of salience patterns can be made by crossing time variables (period and span) with source attributes (language, editorial scope, location).
URL to related tool: https://claudegrasland.shinyapps.io/newsmig2/