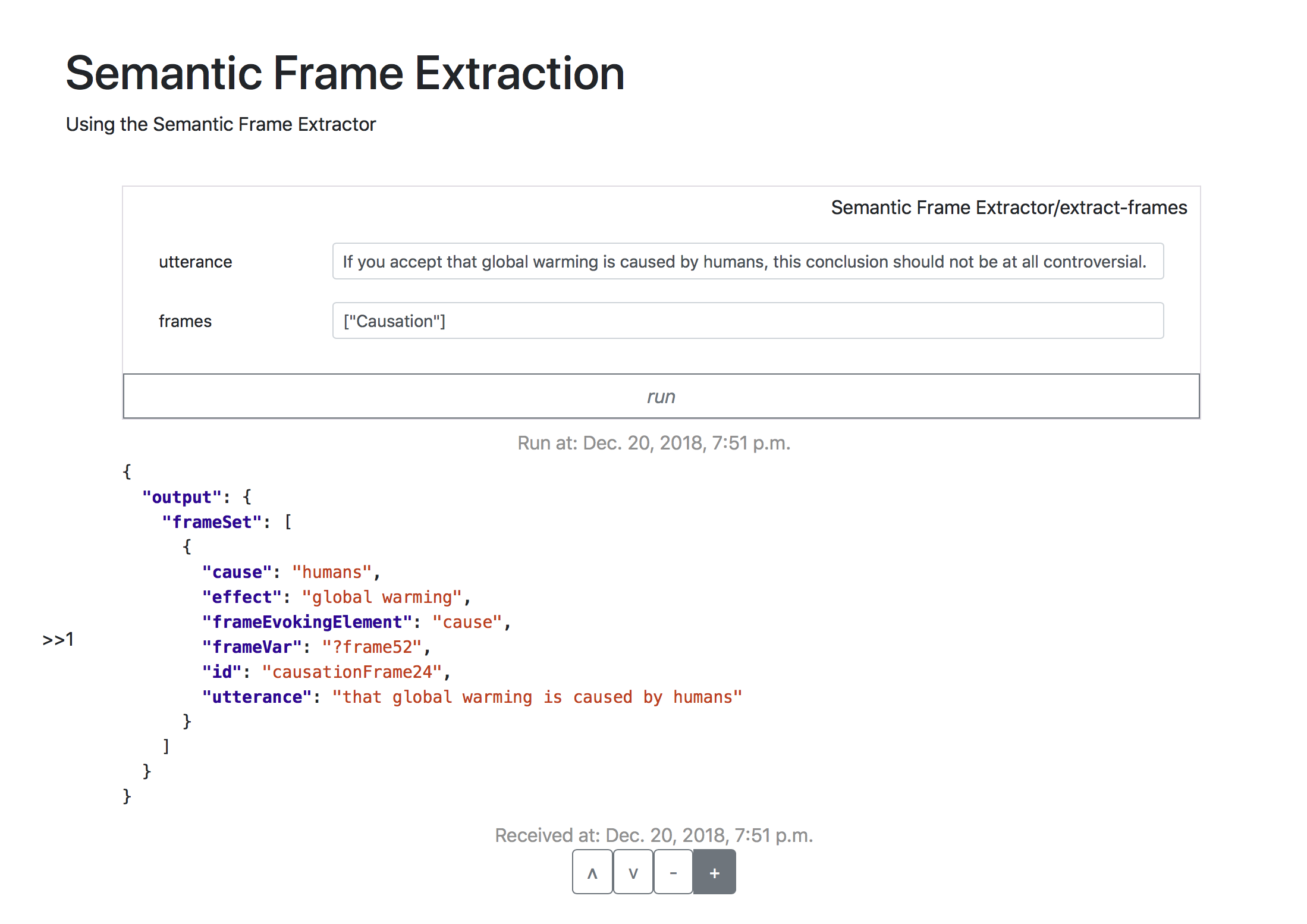
A new Penelope Component, called Semantic Frame Extractor is now online!
Frame semantics is commonly used as a methodology for representing the meaning of linguistic utterances. While semantic frames have successfully been formalised on a large scale, it is still a major challenge to automatically extract them from raw text. This Penelope component overcomes this challenge by using precision language processing techniques. Concretely, the component takes a sentence (or a list of texts) and a frame of interest (e.g. ‘Causation’) as input and returns all instances of this frame, and its frame elements, that occur in the sentence (or list of texts). The language processing part of the semantic frame extractor has been developed within the Fluid Construction Grammar (FCG) framework.
The OpenAPI specification of the component is available at https://app.swaggerhub.com/apis/EHAI/Semantic-Frame-Extractor-API/1.0.0. As all components, it can be used form any programming languages are via Penelope interfaces such as the Penelope Workbench.